Cassandra Architecture
Part 1

Lead @Engineering
What is Cassandra?
Cassandra is defined as an open-source NoSQL data storage system that leverages a distributed architecture to enable high availability, scalability, and reliability, managed by the Apache non-profit organization.
Cassandra components?
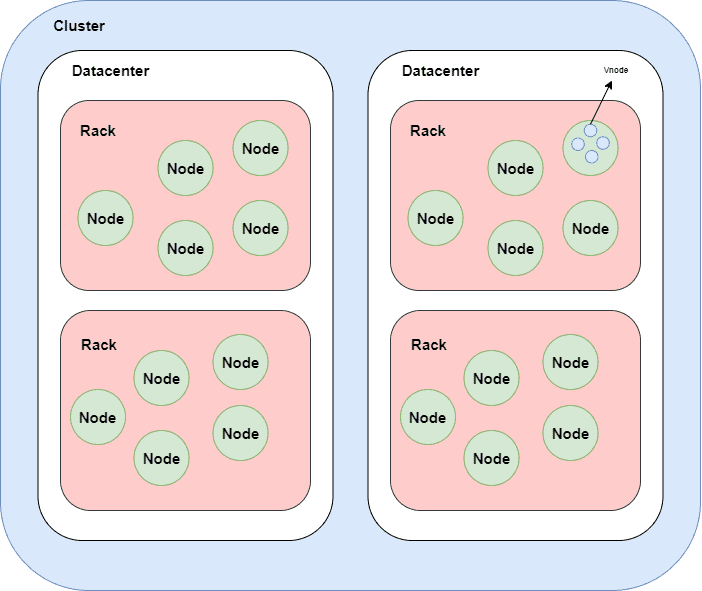
A cluster is a component that contains one or more datacenters. It's the most outer storage container in the database. One database contains one or more clusters. Inside cluster we have datacenters. Inside datacenters, we have racks, that contain nodes by default 256 virtual nodes. (Newer versions of Cassandra use virtual nodes or vnodes)
Database -> Clusters -> Data-centers -> Racks -> Nodes
Cassandra data model?
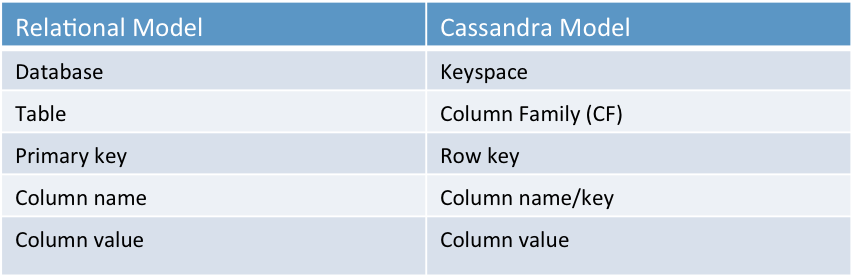
There are several key components of the Cassandra data model:
Keyspace: A keyspace is a logical container for a set of tables in Cassandra. It is similar to a database in a traditional relational database management system.
Table/Column Family: Column family in Cassandra is a collection of rows that are organized into columns. Column family can be configured to store data in different ways, such as with a single partition or with multiple partitions across different nodes.
Column: A column in Cassandra represents a single data element in a column family.
Partition key: The partition key is a special column or set of columns that determines how data is distributed across the nodes in a Cassandra cluster. The partition key is used to determine which node a particular piece of data belongs on.

How data is distributed?
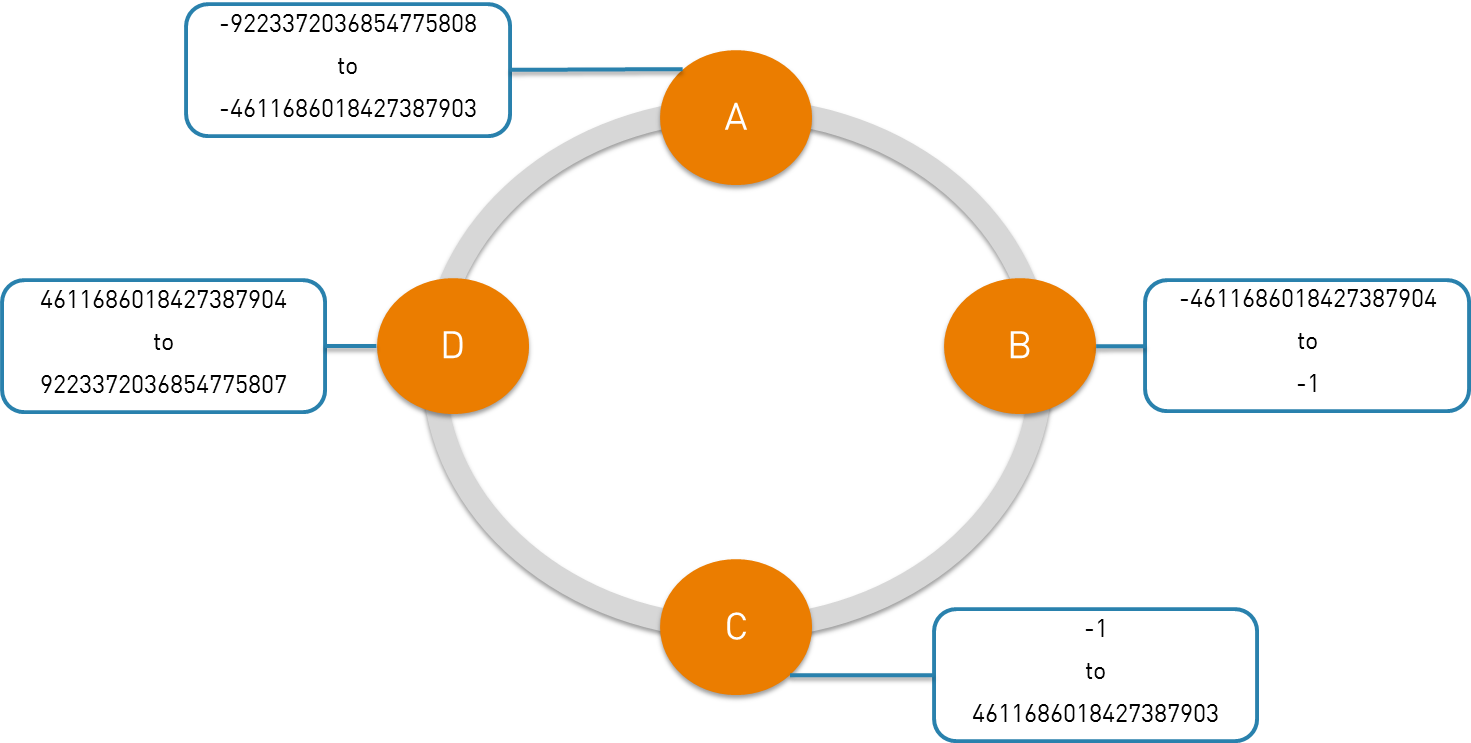
Cassandra uses a partitioner (internal component) to distribute data across cluster nodes. A partitioner determines where each piece of data has to be stored. The partitioning process is completely automatic and transparent.
Basically the partitioner is a hash function, computes a token for each partition key (Partition Key = Row Key). Depending on the partitioning strategy, each node of the cluster is responsible of a token. Below a picture for the partitioning process.
How Cassandra works?
Cassandra works with a peer-to-peer architecture data model, which means that each instance or node is connected to more nodes making up clusters.
Cassandra allows communication between nodes and performs fault detection to reveal any damaged nodes in a cluster to prevent the risk of failure. If outdated data is detected in one of the nodes, Cassandra replicates data from healthy nodes and repairs the damaged ones.
Writing Data
Cassandra is well known for it's impressive performance in both reading and writing data.
When data is written it is connected to any node in the cluster which is called coordinator and it logs data into on-disk commit log and then writes to a memory-based structure called a memtable. When a memtable’s size exceeds a configurable threshold, the data is written to an immutable file on disk called an SSTable. Buffering writes in memory so that writes become a fully sequential operation, with many megabytes of disk I/O happening at the same time, rather than one at a time over a long period. This architecture gives Cassandra its legendary write performance.
Because of the way Cassandra writes data, many SSTables can exist for a single Cassandra logical data table. A process called compaction occurs on a periodic basis, coalescesing multiple SSTables into one for faster read access.
Few things to consider
What is SSTables?
SSTable is an immutable file for the row storage and every write includes the timestamp when we wrote SSTables. Its partition can be spread across the multiple SSTables and same data or column can be in multiple SSTables.
What will we do with the SSTables and how will we merge them?
We will merge all the SSTables into one SSTables but then we will face issues regarding multiple columns and partitions. For removing the above problems, we will use compaction to merge the data which keeps only latest timestamp & discard the others. Only for compaction, we are keeping the Timestamp. Now we can easily back-up the data once it writes on the disk.
Reading Data
Reading data from Cassandra involves a number of processes that can include various memory caches and other mechanisms designed to produce fast read response times. For a read request, Cassandra consults an in-memory data structure called a Bloom filter that checks the probability of an SSTable having the needed data. The Bloom filter can tell very quickly whether the file probably has the needed data, or certainly does not have it. If answer is a tenative yes, Cassandra consults another layer of in-memory caches, then fetches the compressed data on disk. If the answer is no, Cassandra doesn’t trouble with reading that SSTable at all, and moves on to the next.